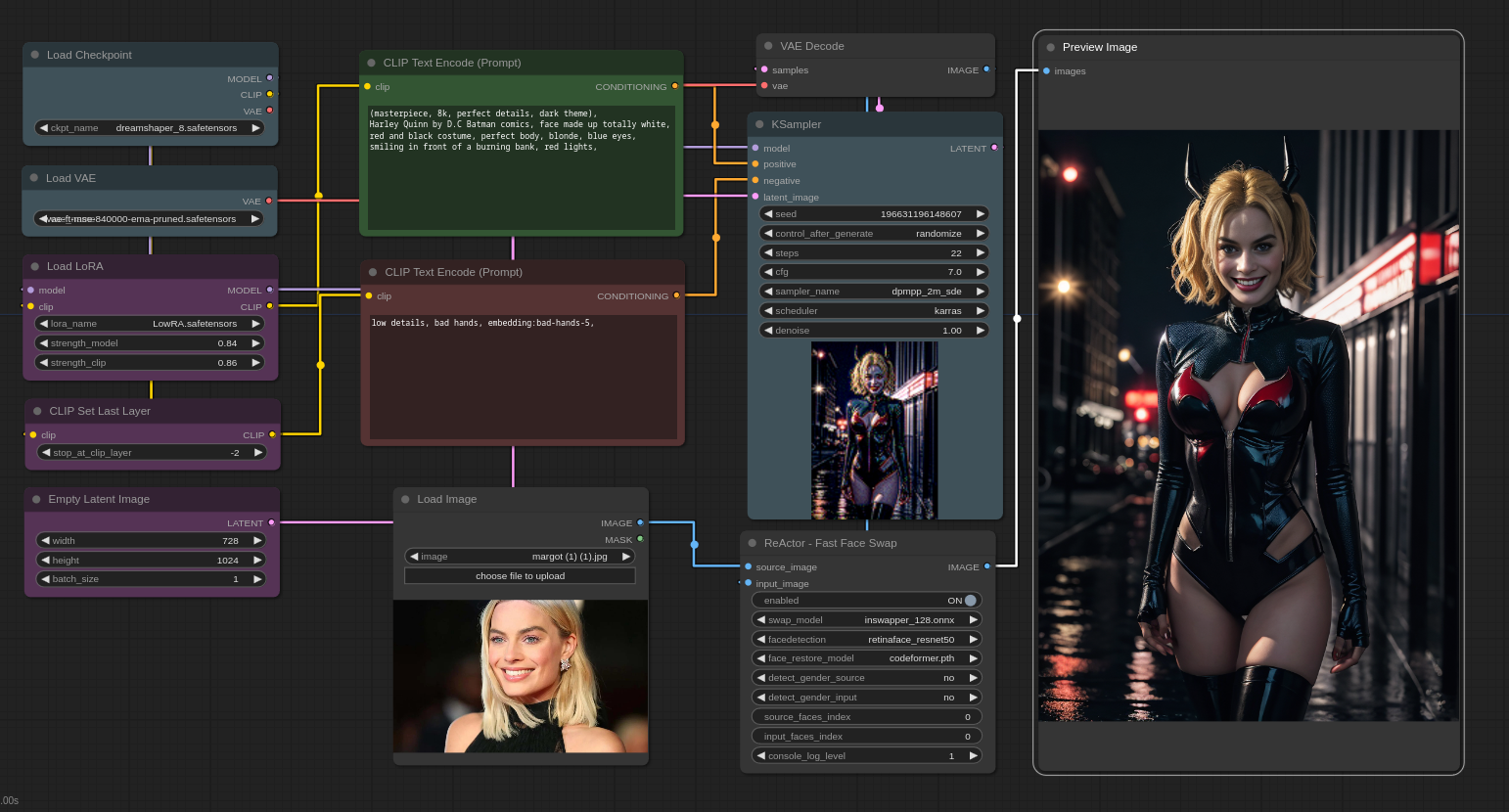
Stable Diffusion and AI stuff
Posted: March 23, 2023, 9:37 pm
So last weekend I started looking into AI generated art and went way down into that rabbit hole.
First, there are a shit-ton of web accessible AI art sites out there, with some of the more popular ones being Midjourney, Blue Willow, even Bing and Google etc have them. I'm here to talk about Stable Diffusion versions you can install on your own PC and not have to pay for or have the cloud do the processing to generate your images. Midjourney is fine I'm sure if you want to go that route.
Stable Diffusion is amazing. After playing around with it for a week I still can't stop fucking around with it.
I have three front ends installed: Auto1111, Invoke AI and Easy Diffusion
Auto1111 - most popular and most supported extensions, LORA, styles, etc but I'm not a fan of the UI
Invoke AI - better UI than Auto1111
Easy Diffusion - newest and my favorite of them. Also easiest to install and work with for newbs while at the same time rapidly gaining features. I use this one as much as I can. I only use Auto1111 for some LoRA that aren't quite yet supported on Easy Diffusion yet (but LoRAs are in beta right now so we're talking a week and they'll be implemented. (install linked below the videos in this post)
All of these work the same way. Through prompts, you tell it what you want to create and then the AI takes over and generates as many images as you want, all different. When you find a version you want, you can fine tune it by keeping the same "seed" and then the AI makes smaller changes.
The above video is an excellent way to see how the use of prompts impacts what the AI generates. He starts out with a basic prompt then starts to modify it so you can see how it progresses.
This video gives some suggestions on things you can do to impact your AI creations.
Installing a stable diffusion front end requires a lot of dependencies, python etc. I recommend using Easy Diffusion:
https://github.com/cmdr2/stable-diffusion-ui
It has a nice easy installer that takes care of most of that stuff for you.
Some great resources:
for models (a model is a resource file trained with images. SD 1.5 or SD 2.0 are the standard default ones but you can get a lot of fine tuned for your interest models here: https://civitai.com/
For prompts:
https://aipromptguide.com/
prompts come in a variety of things: lighting effects, details, textures etc. You can also use the style of something like 20,000 artists.
for example the famous fantasy artists Brothers Hildebrandt, you could apply the style "Brothers Hildebrandt" for their combined work or just the individual brother Greg Hildebrandt or Tim Hildebrandt and the AI will use their style as part of your generated image.
you can also just say "oil painting" or "airbrushed" and the AI will use that style. You can combine/mix two artist, various styles etc.
You have both positive and negative prompts. Here's an example taken from this model:
https://civitai.com/models/4201/realistic-vision-v13
Realistic Vision V1.3
if you go to that link above and see the images, if you click on the little "i" icon in the bottom right of each picture you can see the exact modifiers used to create the image. If you set all the parameters the same, you probably wont get exactly the same image but very close as the AI still does it's thing.
note for Aslanna: This will take everything your 3080ti has got to give. It sucks down VRAM and GPU power like nobody's business. Totally justifies the 3080ti and even a 3090/4090 with even more VRAM.
You can train your own models. That's not the easiest thing to do yet but I tried it. To do it, you take like 15 quality face shots (or whatever you're training) of a person then feed them to the trainer in Auto1111 or (i use) stand alone Koyha trainer, and it starts working it, 15 images are processed about 1500 times total to produce the end result. Takes some time and processing muscle but for what I tried, it worked great. I could recognize the face when I used the model to make images.
-----
I haven't included any of my images created here but they are amazing. I'm sold on AI and just over the past week, by following developments, things are advancing exponentially in AI.
It won't be long (my guess 5-10 years the way AI is training AI faster and faster) before you'll use something like ChatGPT combined with video version of stable diffusion and tell it "Create a five star movie, 120 minutes long, theme: ninjas fighting pirates, starring Brad Pitt (with one wooden leg), Johnny Depp, a 30 year old John Wayne, and (myself) as the villain, set on Mars", video format: virtual reality" and you'll get a movie that's watchable with an original script.
First, there are a shit-ton of web accessible AI art sites out there, with some of the more popular ones being Midjourney, Blue Willow, even Bing and Google etc have them. I'm here to talk about Stable Diffusion versions you can install on your own PC and not have to pay for or have the cloud do the processing to generate your images. Midjourney is fine I'm sure if you want to go that route.
Stable Diffusion is amazing. After playing around with it for a week I still can't stop fucking around with it.
I have three front ends installed: Auto1111, Invoke AI and Easy Diffusion
Auto1111 - most popular and most supported extensions, LORA, styles, etc but I'm not a fan of the UI
Invoke AI - better UI than Auto1111
Easy Diffusion - newest and my favorite of them. Also easiest to install and work with for newbs while at the same time rapidly gaining features. I use this one as much as I can. I only use Auto1111 for some LoRA that aren't quite yet supported on Easy Diffusion yet (but LoRAs are in beta right now so we're talking a week and they'll be implemented. (install linked below the videos in this post)
All of these work the same way. Through prompts, you tell it what you want to create and then the AI takes over and generates as many images as you want, all different. When you find a version you want, you can fine tune it by keeping the same "seed" and then the AI makes smaller changes.
The above video is an excellent way to see how the use of prompts impacts what the AI generates. He starts out with a basic prompt then starts to modify it so you can see how it progresses.
This video gives some suggestions on things you can do to impact your AI creations.
Installing a stable diffusion front end requires a lot of dependencies, python etc. I recommend using Easy Diffusion:
https://github.com/cmdr2/stable-diffusion-ui
It has a nice easy installer that takes care of most of that stuff for you.
Some great resources:
for models (a model is a resource file trained with images. SD 1.5 or SD 2.0 are the standard default ones but you can get a lot of fine tuned for your interest models here: https://civitai.com/
For prompts:
https://aipromptguide.com/
prompts come in a variety of things: lighting effects, details, textures etc. You can also use the style of something like 20,000 artists.
for example the famous fantasy artists Brothers Hildebrandt, you could apply the style "Brothers Hildebrandt" for their combined work or just the individual brother Greg Hildebrandt or Tim Hildebrandt and the AI will use their style as part of your generated image.
you can also just say "oil painting" or "airbrushed" and the AI will use that style. You can combine/mix two artist, various styles etc.
You have both positive and negative prompts. Here's an example taken from this model:
https://civitai.com/models/4201/realistic-vision-v13
Realistic Vision V1.3
The negative prompts help to remove typical unwanted things from the image you're trying to generate.RAW photo, a close up portrait photo of 26 y.o woman in wastelander clothes, long haircut, pale skin, slim body, background is city ruins, (high detailed skin:1.2), 8k uhd, dslr, soft lighting, high quality, film grain, Fujifilm XT3
Negative Prompt:
(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck
if you go to that link above and see the images, if you click on the little "i" icon in the bottom right of each picture you can see the exact modifiers used to create the image. If you set all the parameters the same, you probably wont get exactly the same image but very close as the AI still does it's thing.
note for Aslanna: This will take everything your 3080ti has got to give. It sucks down VRAM and GPU power like nobody's business. Totally justifies the 3080ti and even a 3090/4090 with even more VRAM.
You can train your own models. That's not the easiest thing to do yet but I tried it. To do it, you take like 15 quality face shots (or whatever you're training) of a person then feed them to the trainer in Auto1111 or (i use) stand alone Koyha trainer, and it starts working it, 15 images are processed about 1500 times total to produce the end result. Takes some time and processing muscle but for what I tried, it worked great. I could recognize the face when I used the model to make images.
-----
I haven't included any of my images created here but they are amazing. I'm sold on AI and just over the past week, by following developments, things are advancing exponentially in AI.
It won't be long (my guess 5-10 years the way AI is training AI faster and faster) before you'll use something like ChatGPT combined with video version of stable diffusion and tell it "Create a five star movie, 120 minutes long, theme: ninjas fighting pirates, starring Brad Pitt (with one wooden leg), Johnny Depp, a 30 year old John Wayne, and (myself) as the villain, set on Mars", video format: virtual reality" and you'll get a movie that's watchable with an original script.